誤差拡散法による減色処理 (令和2年度10月 応用情報 午後問3 解答・実装)
IPAの令和2年度の応用情報技術者試験(AP)が10/18(日曜日)に実施された。
アルゴリズムの問題で誤差拡散法による減色処理をテーマにした出題があり、興味深いのでC言語で実装してみた。
実装手順を解説する。(解答は最後につける)。
アルゴリズムの概要の理解
まず、問題文を読んで、どういったアルゴリズムなのかを理解しておく。
画像の情報量を落として画像ファイルのサイズを小さくしたり、モノクロの液晶画面に画像を表示させたりする際に、 減色アルゴリズムを用いた画像変換を行うことがある。
誤差拡散法は減色アルゴリズムの一つである。
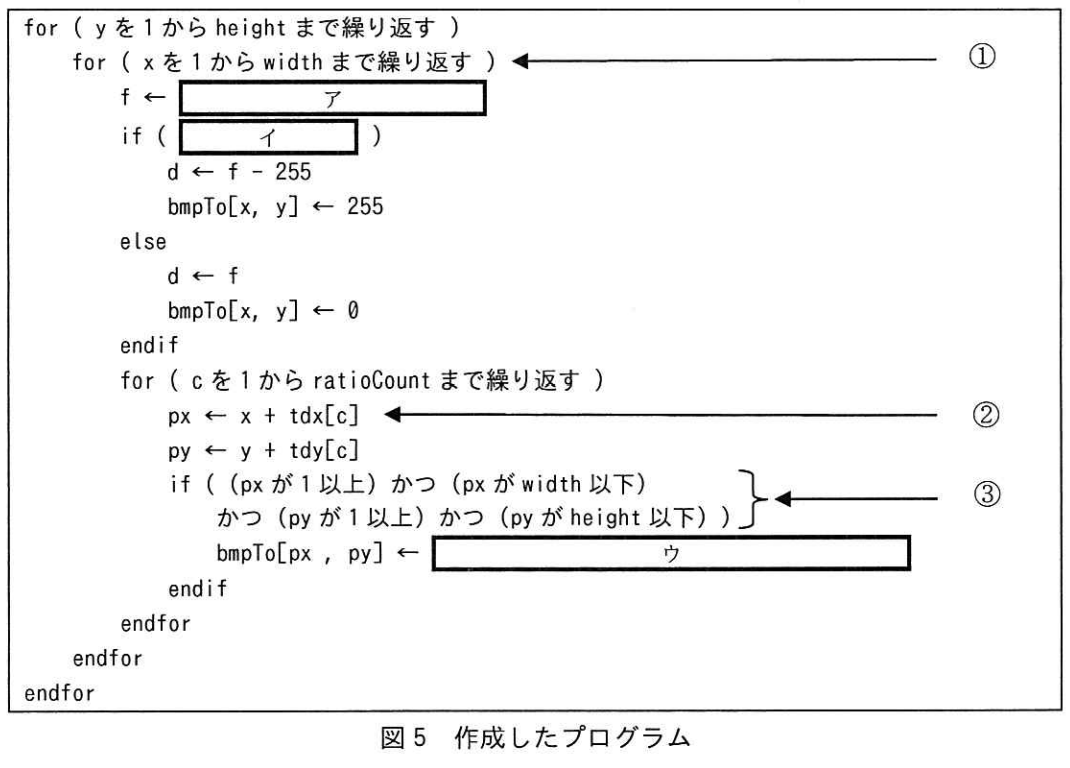
誤差拡散法を用いて、階調ありのモノクロ画像を、黒と白だけを使ったモノクロ2値の画像に画像変換した例を図1に示す。階調ありのモノクロ画像の場合は、各ピクセルが色の濃淡をもつことができる。
濃淡は輝度で表す。
輝度0のとき色は黒に、輝度が最大になると色は白になる。
モノクロ2値の画像は、輝度が0か最大かの2値だけを使った画像である。
階調という言葉は聞き慣れないが、英語ではshadeもしくはgradationで、色の濃淡の変化のことらしい。
1ピクセル1チャンネルにどれくらいの階調をもたせるかというと、場面により様々だが、よく見られるのは1バイト、つまり256階調のようだ。
256の値を取るようなものは人間が鑑賞する分には綺麗で良いものだが、計算機にとってはデータ量も多く、分析もしづらい。
これを2値化(binarization)することで、データ量は少なくなり、画像の分析にも繋げやすくなる。
2値化の最もナイーブな方法は、128を境にして、0と255のどちらかにしてしまうことだが、こうすると、 周辺はそれなりに濃いが一箇所だけ薄いところが白くなったり、周辺はそれなりに薄いが一箇所だけ濃いところが黒くなったり、 また薄いがベタっと塗られている部分が一様に消されてしまったり、あまりきれいにならない。
できれば連続的に変換して、元の画像らしさを残したい場合は、もう少し工夫する必要がある。
それがこの問題のバックグラウンドである。
[誤差拡散法のアルゴリズム]
画像を構成するピクセルの輝度は、1ピクセルの輝度を8ビットで表す場合、0~255の値を取ることができる。
0が黒で、255が白を表す。
誤差拡散法では、次の二つの処理をピクセルごとに行うことで減色を行う。
① 変換前のピクセルについて、白に近い場合は輝度を255、黒に近い場合は輝度を0としてモノクロ2値化し、その際の輝度の差分を評価し、輝度の誤差Dとする。
例えば、変換前のピクセルの輝度が233の場合、変換後の輝度を255とし、輝度の誤差Dは、223-225から、-32である。
② 事前に定義した誤差拡散のパターンに従って、評価した誤差Dを周囲のピクセル(以下、拡散先という)に拡散させる。
拡散先の数が4の場合の、誤差拡散のパターンの例を図2に、減色処理の手順を図3に示す。
なお、拡散する誤差の値は整数とし、小数点以下は切り捨てる。
要するに適当なパターンを事前に用意しておく。
黒っぽいけど黒じゃない色を黒に変換する、あるいは白っぽいけど白じゃない色を白に変換する。
その時に生じる誤差をパターンに沿って周囲に伝搬させる。
ナイーブに0と255にするより「なめらか」っぽい画像ができるだろう、というわけ。
テストデータの用意
まずは、テストデータを用意する。
画像処理分野でよく使われているのは、レナという名前の女性の画像だ。

今回、画像のフォーマットは、あらかじめパースしやすいPGM形式に変換しておく。
まずは、画像ファイルの読み込み書き込みをしなければならないが、その手間を小さくするためである。
外部ライブラリを使えば、たいていのファイル形式が読めると思うが、画像解析は専門でないので、
そういうライブラリを探すのも面倒と感じてしまう。
ファイル形式の変換には、ImageMagickという神ツールがあり、以下のコマンドでBMPからPGMへの変換は終わる。
$ convert lena-gray.bmp lena-gray.pgm
画像ファイルの読み込み・書き込み
今回画像はビットマップデータとして扱うので、単純な構造体で、このように定義する。
typedef struct Image {
int width;
int height;
uint8_t* data;
} Image;
そして、読み込み・書き込みのインタフェースを決める。
// PGMをロードする
// dataは動的確保される
static Image load_pgm(const char* path);
// Imageをpgmとして保存
static bool save_pgm(const Image* img, const char* path);
ロードしたデータは動的に確保したメモリに入れることにするので、解放用の関数も用意しておこう。
// dataを解放する
static bool destroy_image(Image* img);
読み込み/書き込み関数は、変換したPGMファイルをxxdコマンドで見ながら、実装していく。
$ xxd lena_gray.pgm | head -2
00000000: 5035 0a35 3132 2035 3132 0a32 3535 0aa0 P5.512 512.255..
00000010: a0a0 9fa1 9ca1 9fa2 9fa0 9e9a a29e 9a9c ................
変換されたPGMファイルはP5フォーマットと言う形で、一番最初のヘッダー部分が次のようになっている。
P5<改行>
<画像の幅=width> <画像の縦=height><改行>
<1ピクセルの最大値><改行>
<データがwidth x height分だけバイナリで入ってる>
load_pgmの実装は次のようになる。
今回は、1ピクセル1バイト、つまり最大値が255のファイルに限定し、そうでないファイルの場合は エラー終了する。
static Image load_pgm(const char* path) {
FILE* fp = fopen(path, "rb");
if (fp == NULL) {
fprintf(stderr, "Cannot open %s\n", path);
exit(1);
}
char buf[1024];
fgets(buf, sizeof(buf), fp);
if (strncmp(buf, "P5", 2) != 0) {
fprintf(stderr, "Unexpected file format.\n");
exit(1);
}
int width, height, max;
if (fscanf(fp, "%d %d", &width, &height) != 2) {
fprintf(stderr, "Unexpected file format.\n");
exit(1);
}
if (fscanf(fp, "%d", &max) != 1) {
fprintf(stderr, "Unexpected file format.\n");
exit(1);
}
if (max != 255) {
fprintf(stderr, "Unexpected file format.\n");
exit(1);
}
// 改行読み飛ばし
fgetc(fp);
printf("[INFO] width: %d, height: %d, max: %d\n", width, height, max);
Image img = {
.width = width,
.height = height,
.data = malloc(height * width * sizeof(uint8_t))
};
if (img.data == NULL) {
fprintf(stderr, "Failed memory allocation.\n");
exit(1);
}
for (int i = 0; i < height * width; ++i) {
int c = fgetc(fp);
if (c == EOF) {
fprintf(stderr, "Failed get char.\n");
exit(1);
}
img.data[i] = c;
}
fclose(fp);
return img;
}
ファイルを開き、ヘッダを読み、メモリを確保し、データを1バイトずつ読んで確保したメモリに格納する。
特に変わった点はないコードだ。
少しエラー処理が多いような気がするが、この程度のエラー処理は実装上のつまらないミスを早めに捉えるのに 役に立つので、積極的に行うべきだ。
save_pgm, destroy_imageの実装は省略するが(リポジトリにある)、 とりあえず、これで画像の読み書きができるようになった。
誤差拡散法の実装
問題文の虫食いの擬似コードを補完しながら実装していく。
いくつか注意事項がある。
tdx, tdy, ratioは並行配列(Parallel Array)になっている。
こういったコードは現実のプログラミングではあまり好まれないが、
構造体を擬似コードで表現するのも説明が増え、面倒だったのだと思われる。
ここでは、問題文通りに並行配列で実装する。
問題文で配列のインデックスは1始まりであるが、C言語では0始まりである。
これは情報処理試験の問題でよくあることだが、よく注意する必要がある。
虫食いコードの補完は、問題文の別の部分を読むとわかる。
ア、fに何かを代入している部分は、図3に、
- 変換前画像の輝度と、変換後輝度配列の同じ要素の値を加算し、これをFとする。
という記述があることから、bmpFrom[x, y] + bmpTo[x, y]と埋められる。
イ、なにかの条件によって、dとbmpTo[x, y]に入れる値を分岐しているところは、これも図3に、
- Fの値が128以上なら変換後輝度配列の輝度を255とし、誤差の値DをF-255とする。Fの値が128未満なら変換後輝度配列の輝度を0とし、誤差の値DをFにする。
という記述から、fが128以上と埋められる。
ウも、
- Dの値について、誤差拡散のパターンに定義された割合に従って配分し、拡散先の要素に加算する。
という部分が対応するが、パターンや割合や配分が擬似コード上どう表されるかは別のところを探す必要がある。
表1のratioやdenominatorの定義を見るとわかり、bmpTo[px, py] + d * ratio[c] / denominatorというのが答えである。
static Image convert_error_diffusion(const Image* img) {
static const int RATIO_COUNT = 4;
static const int TDX[] = {1, -1, 0, 1};
static const int TDY[] = {0, 1, 1, 1};
static const int RATIO[] = {7, 3, 5, 1};
static const int DENOMINATOR = 16;
int width = img->height;
int height = img->width;
uint8_t* bmp_from = img->data;
short* bmp_to = (short*)calloc(height * width, sizeof(short));
if (bmp_to == NULL) {
fprintf(stderr, "Failed memory allocation.\n");
exit(1);
}
for (int y = 0; y < height; ++y) {
for (int x = 0; x < width; ++x) {
int f = bmp_to[y * width + x] + bmp_from[y * width + x];
short d;
if (f >= 128) {
d = f - 255;
bmp_to[y * width + x] = 255;
} else {
d = f;
bmp_to[y * width + x] = 0;
}
for (int c = 0; c < RATIO_COUNT; ++c) {
int px = x + TDX[c];
int py = y + TDY[c];
if (px >= 0 && px < width && py >= 0 && py < height) {
bmp_to[py * width + px] += d * RATIO[c] / DENOMINATOR;
}
}
}
}
Image converted = {
.width = width,
.height = height,
.data = malloc(width * height)
};
if (converted.data == NULL) {
fprintf(stderr, "Failed memory allocation.\n");
exit(1);
}
for (int i = 0; i < width * height; ++i) {
converted.data[i] = bmp_to[i];
}
free(bmp_to);
return converted;
}
これで一通り実装したものをテストした結果は以下のようになる。
いちおう、xxdコマンドで中身が2値化されているかを確認しておこう。
$ xxd lena-gray-error-diffusion-1.pgm | head -2
00000000: 5035 0a35 3132 2035 3132 0a32 3535 0aff P5.512 512.255..
00000010: 00ff ff00 ffff 00ff ff00 ffff 00ff ff00 ................
たしかに、データ部分が0xffと0x00だけで構成されるようになっている。
画質の向上
問題文には続きがあり、横方向に画像をなめる順番を左から右とするか、右から左とするかを、交互にすることで 画質の向上を図っている。
これも実装してみよう。
y座標が偶数のとき、ピクセルを右から左に処理するので、エはy、オは2である。
C言語と擬似コードでインデックス始まりが違うので、偶奇も反転しなければならないような気もするが、 やりたいことは「交互に」処理するということなので、ここではケアしない。
カは、tx = 1のときに、x = width、tx = widthのときに、x = 1になるような一次式を入れればよく、
width - tx + 1もしくはwidth - x + 1となる。
C言語での実装の変更部分は以下のようになる。
インデックス始まりの違いが、式の違いを生んでいる。
for (int tx = 0; tx < width; ++tx) {
int x = tx;
if (y % 2 == 0) {
x = width - tx - 1;
}
for (int c = 0; c < RATIO_COUNT; ++c) {
int px = x - TDX[c] + (2 * TDX[c] * (y % 2));
この変更によるテストデータの処理結果は以下のようになる。
データがそれなりに大きいテストデータを使ったせいか、違いは余りわからない。
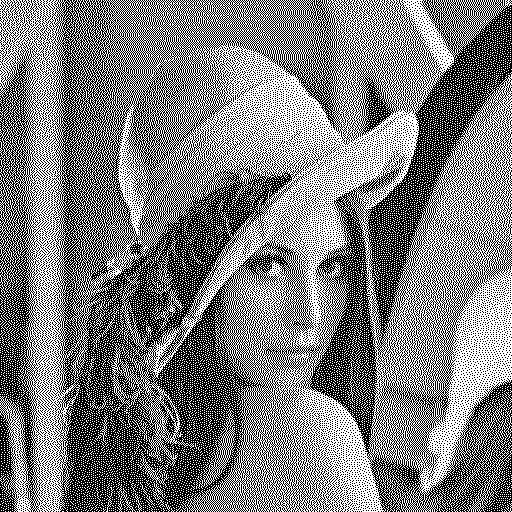
速度の向上
問題文では速度の向上についても触れている。
③のif文は、プログラムの終了までに【 キ 】回呼び出され、そのたびに、条件判定における比較演算と論理演算の評価が、あわせて最大で【 ク 】回行われる。ここでの計算量が少なくなるようにプログラムを改修することで、処理速度を向上させることができる可能性がある。
キは、上からfor文をたどって数えれば、width * height * ratioCountだとわかる。
クは、最悪ケースの評価数なので、単純に比較演算と論理演算を数え上げて、7である。
ところで、これで処理速度が向上するかというと、実は微妙な問題がある。
というのは、現代のマシンは大抵投機実行を行うからだ。
ほとんどの場合③のif文はtrueだとマシンが理解し、実行時には、条件式をチェックする前に代入が起こる。
現代のマシンはとても賢い。
また、この手の問題は実は、loop-unswitchingというコンパイル時最適化の問題でもある。
この問題の場合、単純なloop-unswitchingより複雑な最適化なので、これを的確に実行してくれるコンパイラがあるかどうかは微妙だが、最適化オプションによっては可能かもしれない。
いずれにしても、この手の最適化をプログラマが手動で行うことは、可読性とのトレードオフがあるため、計算上のボトルネックとなっている場合にのみ行うべきであり、慎重であるべきだ。
今回既にC言語での実装があるので検証も可能だが、後の課題としておく。
解答
設問1
(1) 黒
(2) 33
設問2
ア: bmpFrom[x, y] + bmpTo[x, y]
イ: fが128以上
ウ: bmpTo[px, py] + d * ratio[c] / denominator
設問3
エ: y
オ: 2
カ: width - tx + 1 または、 width - x + 1
設問4
キ: width * height * ratioCount
ク: 7